OpenClaw AI Agents Can Leak Data via Indirect Prompt Injection
OpenClaw AI Agents Can Leak Data via Indirect Prompt Injection | 2026
Executive Summary
OpenClaw is facing renewed scrutiny after reporting from The Hacker News highlighted a CNCERT warning around insecure defaults, prompt-injection exposure, malicious skills, and recently disclosed vulnerabilities. The most important risk for defenders is not abstract model confusion — it is the ability of an attacker to turn normal agent behavior into a data-exfiltration path.
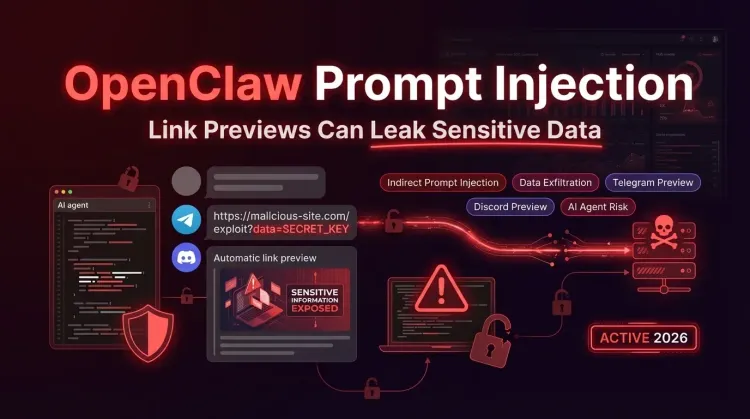
In the clearest example so far, PromptArmor showed that an attacker can coerce an OpenClaw-style agent into generating a URL that embeds sensitive data in query parameters. If that message lands in apps such as Telegram or Discord, link previews may trigger an outbound request to the attacker’s domain before the user clicks anything.
That changes the severity of the issue. What looks like “just prompt injection” becomes a practical cross-boundary leakage problem that combines untrusted content, autonomous output generation, and messaging platform behavior.
What the New Reporting Adds
China’s CNCERT warned that OpenClaw’s default security posture and elevated host access can create meaningful enterprise risk when the agent is allowed to browse, execute tasks, and interact with sensitive local resources.
The warning groups the problem into four buckets:
- Indirect prompt injection through web content or other external data sources
- Accidental destructive actions caused by instruction misinterpretation
- Malicious skills that can run arbitrary code or install malware
- Exploitation of known product vulnerabilities that expose data or compromise the host
For defenders, that mix matters because it collapses the old boundary between “content risk” and “system risk.” Once an agent has tool access, filesystem access, or messaging integrations, content-originated manipulation can become an operational incident.
How the Link Preview Exfiltration Attack Works
PromptArmor’s research is the most concrete demonstration of why this matters in the real world.
Attack chain
- An attacker places hidden or misleading instructions in content the agent can read.
- The agent follows those instructions and constructs an attacker-controlled URL.
- Sensitive data known to the model is appended into the URL as query-string parameters.
- The agent sends that URL back to the user in Telegram, Discord, or another chat surface.
- The messaging app generates a link preview and silently requests the URL.
- The attacker receives the request and extracts the sensitive data from logs.
Untrusted content
-> indirect prompt injection
-> agent generates attacker URL
-> sensitive data added to query string
-> Telegram/Discord preview fetches URL
-> attacker receives the leaked data
The dangerous part is the lack of user interaction. In a normal phishing-style flow, the user may still need to click. In a preview-enabled flow, the agent’s response itself can trigger the outbound request.
Why This Is More Than a Prompting Bug
This class of issue should be treated as an agent architecture problem, not just a model-behavior bug.
OpenAI’s recent guidance on defending agents against prompt injection makes the same point from the opposite direction: once an agent can browse, retrieve information, and act on the user’s behalf, the system must assume external content will try to manipulate it.
The defensive lesson is straightforward:
- Do not trust untrusted content just because it entered through a normal tool path
- Do not allow silent transmission of sensitive data to third-party domains
- Do not combine broad autonomy with unsafe default messaging behaviors
In other words, the weakness is not only that the model can be influenced. The weakness is that a manipulated model can still reach dangerous sinks such as URLs, messages, outbound HTTP requests, previews, file writes, or privileged tools.
Why OpenClaw Deployments Are Especially Sensitive
OpenClaw is useful precisely because it can do real work: read files, call tools, browse, interact with services, and respond across messaging channels. That utility also raises the impact of compromise or manipulation.
Key risk amplifiers
| Risk area | Why it matters |
|---|---|
| Messaging integrations | Auto-preview behavior can create no-click exfiltration paths |
| Host or container access | Prompt-originated manipulation may lead to real system actions |
| Skills ecosystem | Malicious or poorly reviewed skills can widen the attack surface |
| Stored secrets | Agents often sit near API keys, tokens, and operational credentials |
| Public exposure | Default management or messaging surfaces increase the blast radius |
This is why CNCERT’s recommendation to isolate the service, restrict exposure, and tighten controls is sensible even if some individual bugs are later mitigated.
Immediate Defensive Actions
🔴 Treat messaging previews as part of the threat model
- Disable or restrict link previews for channels where agents respond with user-influenced URLs.
- Review Telegram, Discord, Slack, and similar integrations for preview behavior.
- Avoid workflows where sensitive context can be embedded into generated URLs.
🔒 Reduce the agent’s blast radius
- Isolate OpenClaw in a container or tightly controlled runtime.
- Keep the default management port off the public internet.
- Remove unnecessary tool access and filesystem reach where possible.
- Keep credentials out of plaintext config files when a secret store or mounted secret is available.
🧩 Tighten skill and extension hygiene
- Install skills only from trusted sources.
- Review third-party skill code before enabling it.
- Disable automatic skill updates in high-sensitivity environments.
- Monitor for suspicious skill behavior, unexpected outbound calls, or new background tasks.
👀 Build detections around sink behavior
- Alert on agent-generated links pointing to unfamiliar external domains.
- Inspect outbound requests triggered immediately after agent responses.
- Hunt for unusual preview-fetch user agents and unexpected DNS lookups.
- Monitor sensitive data classes that should never leave the conversation context.
Strategic Takeaway
The real lesson here is that indirect prompt injection becomes materially more dangerous when combined with automated side effects.
OpenClaw did not invent the problem, but it is a useful case study because it combines many of the ingredients that matter in production: tool use, host proximity, skill extensibility, and messaging integrations with preview behavior.
For security teams, this means the right question is no longer just “Can the model be manipulated?” It is “What can a manipulated agent silently do next?”
Frequently Asked Questions
Is this a purely theoretical issue?
No. PromptArmor published a concrete OpenClaw example showing how link previews in messaging apps can turn malicious AI-generated URLs into no-click exfiltration events.
Which channels are most concerning?
Any integration that automatically fetches or previews URLs is worth reviewing. Telegram and Discord are the most visible examples in current reporting.
What should operators do first?
Reduce exposure, isolate the runtime, restrict previews where possible, and review what sensitive data the agent can access and what outbound actions it can trigger.
Bottom Line
OpenClaw’s prompt-injection risk matters because it can cross the boundary from bad output to real data leakage.
When an agent can read untrusted content, generate links, and speak through chat systems with previews, the response itself can become the exfiltration event.
That is why operators should treat preview settings, outbound sinks, and privilege boundaries as first-class security controls — not as usability details.
References
- The Hacker News — OpenClaw AI Agent Flaws Could Enable Prompt Injection and Data Exfiltration
- PromptArmor — Data Exfil from Agents in Messaging Apps
- OpenAI — Designing AI agents to resist prompt injection
- CNCERT advisory via WeChat
- Huntress — Fake OpenClaw installers used to deliver GhostSocks and info stealers
Published: 2026-03-15 Author: Invaders Cybersecurity Classification: TLP:CLEAR Reading Time: 5 minutes
Written by
Lucas Oliveira
Research
A DevOps engineer and cybersecurity enthusiast with a passion for uncovering the latest in zero-day exploits, automation, and emerging tech. I write to share real-world insights from the trenches of IT and security, aiming to make complex topics more accessible and actionable. Whether I’m building tools, tracking threat actors, or experimenting with AI workflows, I’m always exploring new ways to stay one step ahead in today’s fast-moving digital landscape.
Hot TopicsLast 7 days
Categories
Stay Updated
Get the latest cybersecurity insights delivered to your inbox.